Web 字体工程实践:DX、子集化与性能平衡
「展示文字」,一个Web 1.0时代就已经成熟的功能。30年后,它还在让中日韩(CJK)开发者们左右为难:
如果追求美观使用网络字体,就会影响用户的加载体验;如果投降使用系统字体,就得忍受不同端的字体差异。
经历过太多这样的取舍之后,属实有点麻木了。麻木之余还有点绝望:
到底有没有一个「简单」方案,能让任何CJK字体无痛集成进任何Web页面?
- 别预加载:看20秒Loading动画,只为加载一个20M的ttf文件😅
- 别裁剪字体:遇到UGC文本直接露馅
- 别影响性能:浏览器缓存应用尽用,Reflow影响降到最低
- 别搞太复杂:Service Worker、客户端预缓存……最后全是兜底流程和维护成本
The Pain of CJK Fonts
CJK字符集太大了。
Noto Sans SC的可变字体文件大小超过17M,包含上万个字形。剔掉中文字符集之后,Noto Sans本身只有2M。网络文件的加载需要时间,粗暴引入这些巨型字体容易导致用户体验出问题。
在追求「体验一致」这个跨平台领域的桂冠之前,我们搞不好先会被「视觉一致」卡住。system-ui 在不同平台上的实现五花八门,让页面里占据最多视觉空间的文字本身在不同系统平台上长得各不相同。
过去5年,我们也尝试过五花八门的各种办法:
| 方案 | 优势 | 问题 | 参考 |
|---|---|---|---|
| 编译时按需裁剪中文字体 | 字体文件大小合理 | 不能应对动态内容 | font-spider |
| 固定3000常用字字体文件 | 能应对部分动态内容 | 如果动态内容中有常用字以外的内容,就只能fallback到备用字体显示 | https://h5.ruguoapp.com/talent-market 即刻App-即刻镇-人才市场 |
| 让用户等待字体加载 | 完全避免FOUT 能应对动态内容 |
加载时间长 需要设计Suspense界面 |
https://h5.xiaoyuzhoufm.com/wrapped-2023 需打开小宇宙查看 |
| Google Fonts Subset | 预切分、按需加载 | Self-Hosting困难 大陆地区不友好 |
Google Fonts launches Japanese support |
| 文本转SVG | 支持可变字体 可以按需加载 |
不支持多行省略等CSS Layout 字体本身特性不兼容 |
font2svg 特殊字体渲染方案 |
其中Google的字体子集化思路非常吸引我:nam-files帮助字体设计师拆分字体集,把一个巨大的ttf文件按unicode区段拆成多个woff2文件,上传到Google Fonts交付使用。
浏览器这边借助CSS font-face 定义中的 unicode-range 属性来实现不同子集woff2的按需加载。这些CSS特性的覆盖率也已经相当不错:
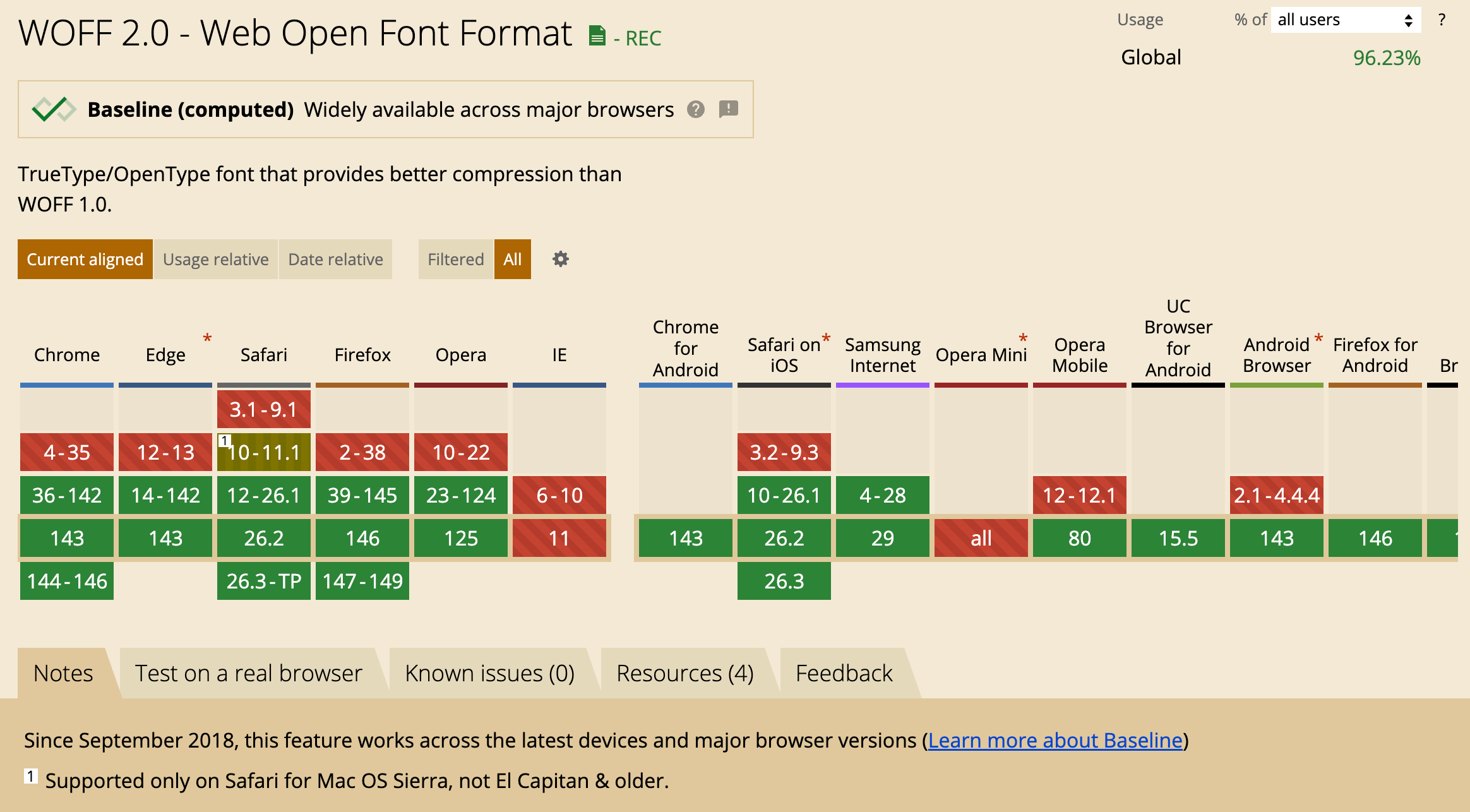

原理可行。但nam-files专为Google Fonts服务,设计师用起来很麻烦不说,平台提供的字体选择又很有限。
我想要的是一个更开放更完整的流程:
- 随便一个ttf文件,都能一键生成woff2子集
- 运行时按需加载woff2子集
- 编译时按需生成静态文本的woff2子集
- 静态子集和运行时动态子集配合互补
- 支持可变字体
- DX优秀,最好插件一键集成
- Self-Hosting,让我能脱离平台自由管理资源
- 减轻字体异步加载导致的视觉跳变和浏览器Reflow
- ...
1个ttf/otf → 1组woff2+1段CSS
在没有自动化工具之前,我只能把ttf/otf文件手动子集化。这是一个痛苦的过程:需要借助fonttools之类的cli工具,分析字体文件支持的unicode范围,读取nam-files里按Region预定义的unicode分组,平均分配每个woff2文件需要包含的文字码点,让子集的大小与数量尽量合理。
现在这些都是过去式了。中文网字计划提供了一个 在线字体分包器,上传文件就能一键 subset。当然了,可变字体也没问题。对OpenType Features有担忧的朋友可以看这个Supported Features表。
以MiSans VF字体为例,子集化后的文件结构差不多是这样的:
MiSansVF/
|---- MiSansVF.min.css
|---- ff52a9365aa49f5a1b0d82a9ea975465.woff2
|---- fc7773401d65c38df2bb6a5499e71fc5.woff2
|---- ...[hash].woff2
把产物托管到CDN上,加一行CSS:
@import 'https://cdn.example.org/MiSansVF/MiSansVF.min.css';
.text {
font-family: "MiSans VF";
}
浏览器就能:
- 在页面渲染“好”这个字时,只拉取“好”这个字所在的woff2子集文件
- 遵守woff2文件的缓存策略,不会重复加载
Fast 4G条件下的效果对比:
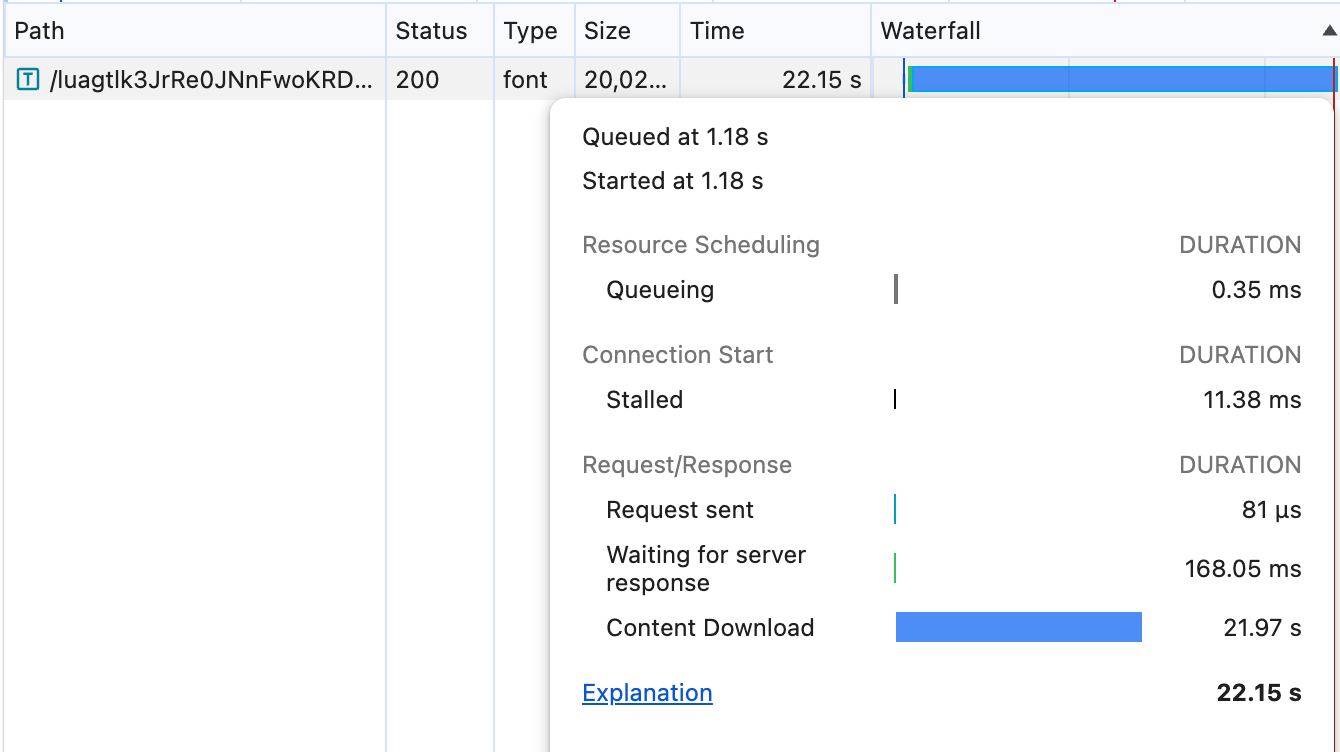
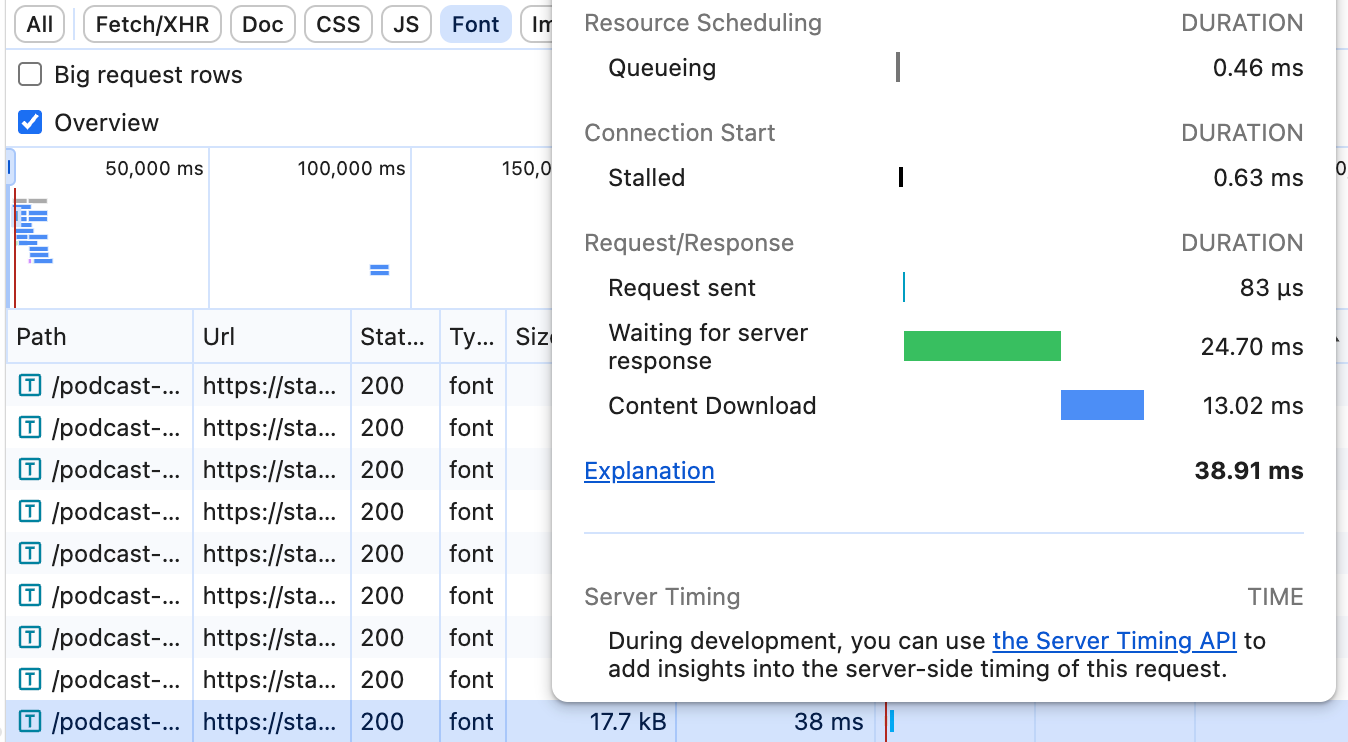
到这里其实就已经够用了。到目前为止我只点了3下按钮,加了1行CSS.
如果和我一样觉得还不够,也可以继续做点加法。
按需编译 + 动态兜底
如果页面中静态文字比较多,我会加个编译时的子集化流程。原因有2个:
- 我能控制分割逻辑,n个页面可以分1个/n个
- 我能控制加载顺序,让页面骨架的文字先加载先显示
只需要引入vite-plugin-font,就能集成按需编译。
虽然名字叫 vite-plugin,得益于rust + wasm的底层实现,它可以支持几乎所有现代前端构建工具,包括 Webpack.
实现原理也不复杂,如果你熟练使用fonttools,配合一些文件扫描,把项目代码中所有中文字符匹配出来,就可以写个脚本,基于一个完整ttf文件裁切出一个 essential.woff2.(小宇宙漫游日的活动网页就是这样手搓的)
按需编译出来的woff2文件当然也可以与CDN上的完整子集们配合互补,注意一下CSS的引入顺序就好了(用css-in-js方案的再多检查检查):
// main.tsx
// 这个 ttf 文件是完整的字体文件,给插件按需生成 woff2 用的
import "../public/MiSansVF.ttf?subsets";
import "./global.font.css";
/* global.font.css 维持不变 */
@import 'https://cdn.example.org/MiSansVF/MiSansVF.min.css';
.text {
/* 由于我们一定知道引入的 font name
* 没必要像文档里那样从 ?subset 导入 name
*/
font-family: "MiSans VF";
}
FOUT/FOIT和Reflow优化
如果页面像即刻人才市场一样是Feed流或Grid卡片,90%以上的文字都由动态文本构成,浏览器需要在FCP的同时加载大量的woff2文件,可能会观察到以下现象:
- 页面上的文字会先部分空白/fallback,随后杂乱无章地变成加载好的字体(FOUT)
- woff2 一个接一个加载好之后,文字分批频繁Reflow,主线程FPS降低,动画可能掉帧
我一直觉得FOUT和FOIT没有绝对的优劣之分,它们只是一种权衡。是先让用户看到「丑一点」的内容好,还是让用户盯着「空白」等待完美呈现好?大家争了很多年也没有标准答案。
但是在用上子集化之后,我们基本上只能告别传统的FOUT方案了。同一段文本中的不同字符可能被拆分到不同的woff2里,有些文本因为子集加载完毕显示出来了,没加载好的文本暂时还只能fallback,看起来就像出Bug了:

CSS 的 font-display 策略里我更喜欢 fallback/optional,但是它不让我控制超时时间,我爱不动。我选择fontfaceobserver精细监控:
const [fontStatus, setFontStatus] = useState<'loading' | 'loaded' | 'error'>('loading')
const contentRef = useRef<HTMLDivElement>(null)
const FONT_LOAD_TIMEOUT = 3000
const styles = {
opacity: fontStatus === 'loading' ? 0 : 1,
fontFamily: fontStatus === 'error' ? 'fallback' : 'custom'
}
// 这里其实有逻辑漏洞,MutationObserver 更通用更健壮
useEffect(() => {
const font = new FontFaceObserver('MiSans VF')
font
.load(contentRef.current?.innerText, FONT_LOAD_TIMEOUT)
.then(() => setFontStatus('loaded'))
.catch(() => setFontStatus('error'))
}, [])
return (
<div ref={contentRef} style={styles}>
{/* Cascading DOMs with dynamic text */}
</div>
)
- 用
dom.innerText去获取DOM下所有"文字"字符串,浏览器自动给清洗好 FontFaceObserver监测对应字符串的woff2文件是不是加载好了,开发者自由控制超时时间,它不干预浏览器本身的字体加载行为- 加载过程中,通过Skeleton/Animation来暂时隐藏内容
- 加载出错/超时后,固定到fallback字体不再变动,以保证组件边界内不同字体不会混合出现
有了FontFaceObserver来帮忙,选择FOIT还是FOUT、超时时间、fallback边界都是属于开发者的自由。
如果要在性能敏感的场景下使用,就换成 document.fonts.load,把「预加载」和「应用字体样式」两步分开,让Reflow尽可能在浏览器空闲时跑:
// 给 document.fonts.load 补个超时能力
function loadFontWithTimeout(fontSpec: string, text: string, timeout = 3000) {
return Promise.race([
document.fonts.load(fontSpec, text), // 兼容性已经很不错
new Promise((_, reject) => {
setTimeout(() => reject(new Error('Font load timeout')), timeout)
})
]);
}
// 改造下 useEffect/MutationObserver
useEffect(() => {
// 只进行网络请求,不影响浏览器渲染
loadFontWithTimeout(`1em "MiSans VF"`, text, 3000)
.then((loadedFonts) => {
// 虽然已经 2025 年了,但你也不能忘记给 SafaIE 打 polyfill
requestIdleCallback(() => {
// 应用字体、触发 Reflow、opacity -> 1
element.classList.add('font-custom');
})
})
.catch(() => {
// element 默认处于 fallback 字体,.font-fallback 只改可见性
element.classList.add('font-fallback')
});
}, [text]);
woff2文件有重叠和不一致会怎样?
前面提到为了更精细的控制,我会在一些场景下选择「按需编译 + 动态兜底」的双重方案,那首先不可避免的就是:
按需子集化出来的woff2文件(STATIC_1.woff2),和CDN上的woff2文件(CDN_1.woff2)必然存在某些文字的重合。
也就是说,如果:
STATIC_1.woff2里面包含了“我能吞下玻璃而不伤身体”这11个字;CDN_1.woff2中包含的是 “我也能吞下玻璃而不伤身体” 这12个字;
即使浏览器已经加载过 STATIC_1.woff2,在遇到 “也” 字时,它还是得下载 CDN_1.woff2。其他11个字的字体被下载了2遍。
好在浏览器这方面的容错做的不错,这并不会引发什么问题。如果对重复下载很敏感,可以考虑把CDN文件也改为编译时动态生成。在 vite-plugin-font 确定本地字体集后,生成一份CDN字体集,跟随网页静态资源一起部署:
代价是这样会造成woff2文件的hash变化,更新一个字就可能会让用户的字体缓存失效。
但浏览器另一个方面的容错做的就不怎么样了。我在实际应用中遇到过一个Edge-case:
CDN_1.woff2是我6个月前上传到CDN的子集化文件之一,它基于MiSans_v1.ttf子集化- 上周我开启了一个新项目,使用插件在本地按需子集化出了
STATIC_1.woff2,但它使用MiSans_v2.ttf子集化 - 字体的family相同,我还是用「按需编译 + 动态兜底」配合
结果会怎样?
—— 浏览器要么完全不加载CDN上的woff2文件,要么完全不加载本地的woff2文件。
虽然对于浏览器在 CJK 排版上的诡异行为已经见怪不怪了,但我还是想下潜到字体文件的二进制结构中看一眼。我对 MiSans_v1.ttf 和 MiSans_v2.ttf 的CMAP进行了比对,确实发现了不同:
--- old.ttx 2025-12-23 11:38:40
+++ new.ttx 2025-12-23 11:38:41
@@ -328,7 +328,6 @@
<map code="0x17e" name="zcaron"/><!-- LATIN SMALL LETTER Z WITH CARON -->
<map code="0x17f" name="longs"/><!-- LATIN SMALL LETTER LONG S -->
<map code="0x181" name="uni0181"/><!-- LATIN CAPITAL LETTER B WITH HOOK -->
- <map code="0x188" name="uni0188"/><!-- LATIN SMALL LETTER C WITH HOOK -->
<map code="0x18a" name="uni018A"/><!-- LATIN CAPITAL LETTER D WITH HOOK -->
<map code="0x18f" name="uni018F"/><!-- LATIN CAPITAL LETTER SCHWA -->
<map code="0x192" name="florin"/><!-- LATIN SMALL LETTER F WITH HOOK -->
@@ -336,17 +335,11 @@
<map code="0x199" name="uni0199"/><!-- LATIN SMALL LETTER K WITH HOOK -->
<map code="0x1a0" name="Ohorn"/><!-- LATIN CAPITAL LETTER O WITH HORN -->
<map code="0x1a1" name="ohorn"/><!-- LATIN SMALL LETTER O WITH HORN -->
- <map code="0x1a5" name="uni01A5"/><!-- LATIN SMALL LETTER P WITH HOOK -->
- <map code="0x1ad" name="uni01AD"/><!-- LATIN SMALL LETTER T WITH HOOK -->
<map code="0x1af" name="Uhorn"/><!-- LATIN CAPITAL LETTER U WITH HORN -->
<map code="0x1b0" name="uhorn"/><!-- LATIN SMALL LETTER U WITH HORN -->
...
原来是 MiSans 偷偷更新过字体!但是这个字体我都不知道它还有版本之分。
而影响浏览器判断的差异似乎也不止是CMAP. 我尝试修改了字体的OS/2表、head/post标志位、fvar等,也都能复现这个问题。
因为实在不精通OpenType,我只能斗胆给一个可能的解释:
如果两个不同的字体使用同一个family,在浏览器眼里通常不是“font fallback”(从family A换到family B),而是同一个family内的多个face(同weight/style/stretch)在做unicode-range互补。当某个字符不在本地subset覆盖范围内,浏览器会尝试在同family、同三元组(weight/style/stretch)下找另一个face的unicode-range能覆盖它,然后触发那个face的下载。而我这么做影响了它的判断。
解决方案的话,无非就是2个选择:
1. 如果还是想用同一个Family Name
CDN上的字体文件分版本,保留一份原始ttf文件用于本地subset。可以考虑在编译时加校验,保证本地subset与CDN子集来自同一源字体构建产物。
MiSansVF/
|---- v1/
|---- MiSansVF.raw.ttf
|---- MiSansVF.min.css
|---- ff52a9365aa49f5a1b0d82a9ea975465.woff2
|---- fc7773401d65c38df2bb6a5499e71fc5.woff2
|---- ...[hash].woff2
2. 如果可以接受本地subset换个名字
由于修改metadata受字体许可限制,vite-plugin-font 可能无法支持更改字体文件本身的 font-family.
如果只是服务内部场景,直接手动修改用于本地subset的源文件ttf/otf:
ttx -o font.ttx MiSans.ttf
# 打开 font.ttx,搜索 <namerecord nameID="1"> / 16 / 4,改文本
ttx -o MiSans_VF_Essential.ttf font.ttx
CSS里就可以显式fallback:
.text {
font-family: 'MiSans VF Essential', 'MiSans VF'
}
角落里的可能三角?
能够落地的技术实现好像总是充满着妥协。但在Web字体这个小角落,似乎又能找到一个打破「性能、体验、成本」不可能三角的平衡点:
- 设计师不再受限于
system-ui,在任何设备上都能完美还原排版意图,20M的中文字体也能放心用 - 工程师不用手动维护繁杂的码表和构建流程,也不再担心构建产物体积爆炸
- 用户能自由感受字体之美,不用忍受几十秒的等待,也不会感受到突兀的布局抖动
在工程解决方案之外,W3C也在推动Incremental Font Transfer提案的标准化。期待有朝一日:你只需引入字体,剩下的交给浏览器。